
במאמר הקודם הוצגו האתגרים המרכזיים בעולם ה-Big-Data, ושני המימדים העיקריים לפתרון אתגרים אלה: In-Memory ו-NoSQL.
במאמר זה נדון בסוגים העיקריים של כלי ה-NoSQL במטרה להבין את השוני ביניהם, ואת סוג המקרים אשר כל אחד מהם בא לפתור.אך עוד לפני שנתחיל – מדוע חשוב למדען נתונים לדעת מה ההבדל בין סוגי ה-NoSQL השונים?
ובכן, כפי שכבר הודגש במאמרים קודמים, בעידן ה-Big-Data מדען נתונים הוא לא רק מנתח נתונים – אלא גם מי שאמור לבחון נתונים חדשים ואת כדאיות קליטתם למערכות הארגון. לאור ריבוי הטכנולוגיות בתחום, האתגר הופך מלימוד של שפה/ סביבת עבודה אחת, ליכולת לימוד של הרבה סביבות עבודה חדשות – מאחר ובכל אחת מהן עשוי להימצא הנתון שיאפשר תובנות עסקיות פורצות דרך.לאחר שהוסברה חשיבות הנושא, להלן פירוט סוגי ה-NoSQL הקיימים כיום.
 מקובל לחלק את כלי ה-NoSQL ל-4 סוגים עיקריים:
מקובל לחלק את כלי ה-NoSQL ל-4 סוגים עיקריים:
1. Key-Value Stores.
2. Column Oriented Stores
3. Document Oriented Stores.
4. Graph Databases.
Key-Value Stores
כפי שצוין במאמר הקודם, אחת הבעיות העיקריות בטיפול בהיקפי נתונים אדירים היא התבססות על שרת יחיד, והפתרון הוא עיבוד מקבילי על מספר מכונות (יכול להגיע גם לאלפי מכונות), כאשר כל מכונה מעבדת חלק קטן מהנתונים.
חלוקת הנתונים הפשוטה ביותר מבוצעת בעזרת 'מפתח' (Key). לרוב, המפתח הוא מזהה ייחודי של האובייקט שנשמר, לדוגמה – המשתמש, הלקוח, הסרט וכיו"ב. הדרך הפשוטה ביותר להבין את העיקרון היא שמירת נתוני הלקוחות שלנו ב-22 מכונות – כאשר כל מכונה מחזיקה לקוחות ששמם מתחיל באות מסוימת.
כמובן שמספר הלקוחות ששמם מתחיל באות מסוימת אינו אחיד בין האותיות, ולכן נדרש ההיבט הנוסף שצוין – סנכרון בין המכונות.
הסנכרון כולל בין השאר הקצאת מקום לנתונים חדשים, חלוקת עומסים, הכפלת נתונים לצרכי גיבוי וכיו"ב.
ברגע שבוצעה החלוקה למפתח (Key), תחת אותו המפתח ניתן לשמור את כלל המידע הקשור אליו, לדוגמה: Facebook (מפתח: מזהה המשתמש; ערך: פרופיל המשתמש – הפיד, אלבומים, מאפייני משתמש), אמאזון (מפתח: מספר לקוח; ערך: היסטוריית הרכישות, מוצרים שנצפו).
חשוב לציין, כי המידע עצמו (Value) אינו קבוע מראש – אלא גולמי (לרוב קובץ טקסט גדול), וניתן לשינוי בהתאם ליישום הספציפי (כולל פענוח – Parsing של התוכן באופן ספציפי ליישום).
מספר דוגמאות לבסיסי נתונים מבוססי Key-Value:
DynamoDB , Redis, Riak.
Column Oriented Stores
ישנם שני סוגים עיקריים של בסיסי נתונים מבוססי עמודות: האחד לצרכים אנליטיים, והשני לצרכי אפליקציות ייעודיות המצריכות עמידה בנפחי עבודה וקצבים מסיביים.
Columnar Database לצרכים אנליטיים:
בעולם ה-Big-Data קיים מספר רב של יישומים אנליטיים. הצורך העיקרי ביישומים אלה הוא פחות ברמת הרשומה הבודדת, אלא בהצגת נתונים מסוכמים, דוגמת ספירה, ממוצעים וכיו"ב.
עבור יישומים מעין אלה, המשמעות של עבודה במבנה רלציוני היא שנדרש לקרוא את כלל הנתונים בטבלה מסוימת (עמודות ורשומות) – גם אם הצורך הוא סיכום של ערכים ברשומה אחת בלבד. לדוגמה, אם קיימות 100 עמודות ומיליון רשומות, הטבלה תידרש לכאורה לסרוק 100 מיליון תאים – גם אם העמודה שאנו צריכים מכילה מיליון תאים בלבד.
פתרון ראשוני של הבעיה הוא פיצול של הטבלה למספר טבלאות קטנות, כאשר בכל טבלה חדשה יש עמודה אחת בלבד. כך, אם נרצה לדוגמה לראות גרף של מספר הלקוחות שהצטרפו בכל יום – כל שנצטרך הוא לעבור על טבלת תאריך ההצטרפות בלבד ולקבץ את הערכים בה.
בהיבט הרשומות – כלל הטבלאות החדשות מסודרות בדיוק באותו הסדר, כך שלדוגמה – אם נתון הגיל של לקוח X מופיע בשורה 1001 בטבלת הגילאים, גם בטבלת מועד ההצטרפות שלו הוא יופיע בשורה 1001.
מאחר וכל טבלה חדשה מכילה ערך בפורמט אחיד, ניתן לחלק כל שאילתה לריצה במקביל על פני מספר רב של מכונות – מה שיאיץ מאוד את זמן העיבוד.
כמובן שקיים מחיר לשינוי המבנה – והוא פעולות ברמת הרשומה הבודדת: עדכון של רשומה בודדת כזו על פני כל הטבלאות יהיה יעיל הרבה פחות מאשר בסיסי נתונים מבוססי רשומה.
דוגמאות לבסיס נתונים מבוסס עמודות: Vertica.
Column Oriented Data Store:
הגישה משלבת את ה'טוב משני העולמות' הן של Key-Value (אחסון/שליפת נתונים גולמיים עבור 'רשומה' מסוימת) והן של Columnar Database (עבודה ברמת עמודה);
על מנת לאפשר גישה לרשומה בודדת, הומצאו בסיסי נתונים מבוססי עמודות מתוחכמים יותר, אשר מציגים מבנה היררכי. במקום להתייחס לעמודה שלמה, או לערך תא במיקום קבוע מסוים של אותה העמודה, עושים שימוש בתפיסת ה-Key-Value לגישה ל'רשומה' מסוימת, ושליפת הערך בהצלבה שבין ה'רשומה' לעמודה.
כך, בהינתן מפתח (key) מסוים, בעמודה מסוימת (column) ובנקודת זמן מסוימת (timestamp) – יימצא ערך אחד בלבד. בשיטה זו יש גם גמישות רבה מאוד בסוג הנתונים הנשמר בכל תא, מבנה בסיסי של Key-Value המתאים לעבודה בנפחי עבודה ומהירות גבוהים מאוד ובקרת גרסאות הנדרשת לעבודה בקצבים מהירים.
דוגמאות לבסיסי נתונים מבוססי עמודות מסוג זה: Cassandra, Hbase.
Document Oriented Stores
לעומת Key-Value Stores המכוונים ליישומים כלליים, כאשר הערכים הנשמרים עבור כל מפתח הם גולמיים וחסרי מבנה מסודר, בסיס הנתונים מבוסס המסמכים נועד לטיפול ספציפי ביישומים הנדרשים לשמור נתונים טקסטואליים.
בסיס הנתונים תומך באופן מובנה בפורמט ייחודי הנקרא Json. הפורמט מאפשר אפיון נתונים בצורה היררכית, כאשר כל שדה בפורמט יכול לכלול ערך אחד או יותר.
כל 'רשומה' בבסיס הנתונים נקראת מסמך (Document). כל מסמך מזוהה באמצעות מפתח (Key), כאשר ה-Value עבורו בנוי מקובץ Json – הכולל שדות וערכים בצורת טקסט. להלן דוגמה של פורמט Json ב-MongoDB (המפתח מיוצג באמצעות השדה "_id", יתר השדות הם ה-value):

במקום שמירת הנתונים בטבלה, אוסף של מסמכים שמור ביישות הנקראת Collection.
לאור המבניות של פורמט Json, בסיסי נתונים מבוססי מסמכים מאפשרים קיום של מודל נתונים חלקי (Semi-Schemaless\ Semi-Structured).
דוגמאות ל-Document Oriented Stores:
MongoDB, CouchDB.
Graph Databases
בסיס נתונים זה הוא השונה מבין ארבעת סוגי ה-NoSQL, ואחד המעניינים שבהם. במקום לחפש דרך כיצד לשנות את מבנה הנתונים כך שיתאים לאחסון, שליפה ועיבוד הנתונים במספר רב של מכונות, בסיסי הנתונים מבוססי גרפים באו על מנת לפתור את בעיות המידול של קשרים בין ישויות בבסיס הנתונים – לדוגמה – קשרים בין אנשים ברשת חברתית, קרבה בין מיקומים גיאוגרפיים, רצף של אירועים, זיהוי הונאות וכיו"ב. מידול של תרחישים מעין אלה בבסיסי נתונים רלציוניים היא אפשרית בעזרת טבלת קשר בין יישות א' ליישות ב', אך שליפות נתונים עבור בעיות מסוג זה דורשות כתיבת שאילתות רקורסיביות אשר גוזלות משאבים רבים.
לדוגמה: חישוב המעגל השלישי של החברים ב-LinkedIn (חברים של חברים של חברים).
בבסיס נתונים רלציוני המידול היה מתבצע בעזרת טבלת הקשרים הבאה:
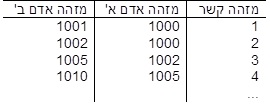
השאילתה הנדרשת לזיהוי אנשי הקשר במעגל השלישי דורשת הצלבה של הטבלה לעצמה פעמיים (או N-1 פעמים במקרה הכללי), מה שגוזל משאבים רבים.
ב-Graph Databases המידול הוא של הקשרים עצמם בין הישויות, כולל תכונות של הקשרים וכיוונם (חד/דו צדדי), והשאילתה מחושבת באופן ישיר:
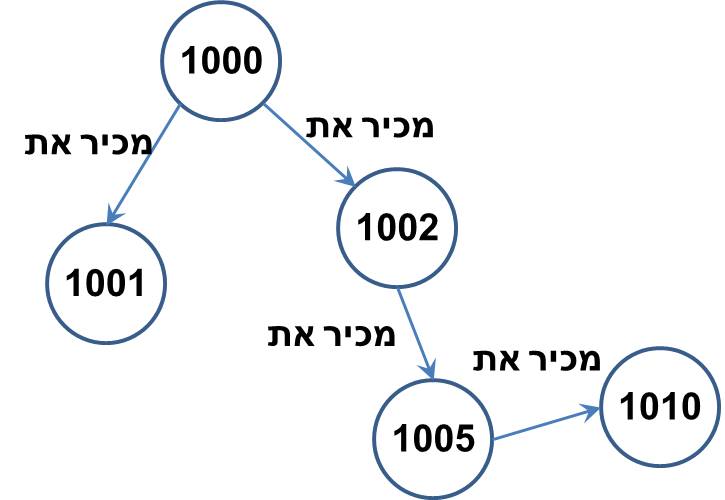
מאחר וקשרים בין ישויות הם לרוב נתונים מובנים מחד, ותחומים יחסית מבחינת נפחי העבודה מאידך (לכל יישות מספר מוגבל של קשרים, גם אם מדובר במספר גבוה), Graph Databases אינם דורשים מעבר לתפיסה מבוזרת של עבודה על מכונות רבות. יחד עם זאת, האתגר ב-Graph Database הוא לרוב מידול נכון של התרחיש בו עוסקים – המחייב חשיבה שונה מאשר ביתר סוגי בסיסי הנתונים.
דוגמאות ל-Graph Databases: Neo4j.
במאמר הבא תוצג תחילת העבודה עם MongoDB, אחד מבסיסי הנתונים הפופולריים ביותר בתחום ה-NoSQL, ואשר מאפשר 'נחיתה רכה' יחסית למי שעושה את צעדיו הראשונים בעולם ה-Big-Data.