
בתהליך טיפוסי של מחקר ניתוח נתונים (Predictive Analytics, Data Mining) קיימים מספר שלבים עיקריים:
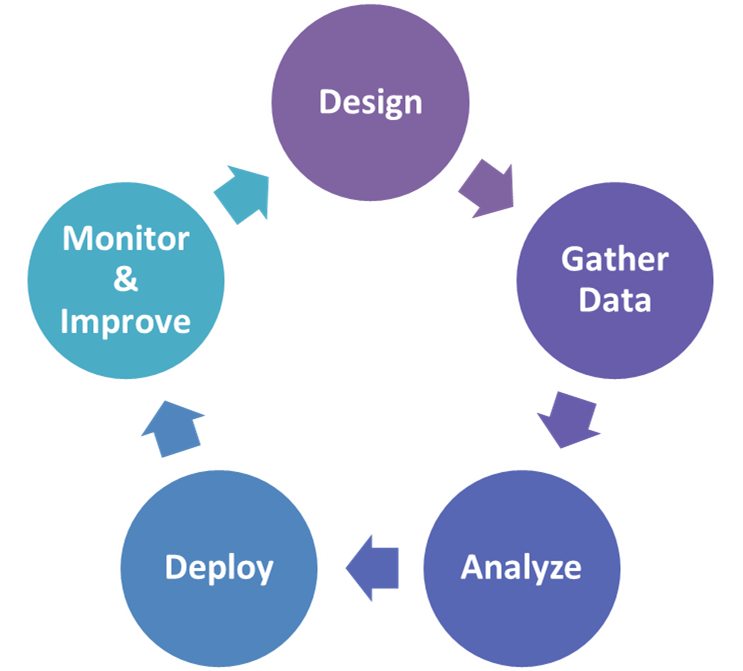
- אפיון
- שליפה ועיבוד נתונים
- ניתוח הנתונים
- מימוש תוצרי הניתוח/ מחקר בקוד
- ניטור התוצאות
תהליך השליפה ועיבוד הנתונים הוא מהמשמעותיים ביותר, מאחר ובמידה רבה שליפה לא נכונה עשויה להביא לתוצאות שגויות Garbage In Garbage Out. התהליך כולל מרכיב טכני רב למדי של קידוד, אשר לעיתים עשוי להגיע לעשרות רבות של שאילתות; על כן הוא בעל פוטנציאל גבוה הן לטעויות והן לחוסר יעילות בשליפות – אשר תתבטאנה בזמן שליפה ו/או עיבוד ארוכים למדי.
מטרת מאמר זה הוא להציג את האפשרויות העומדות לרשותנו לבצע את תהליכי עיבוד הנתונים, ולסקור את היתרונות והחסרונות של כל שיטה.
המאמר יחולק ל-2: בחלק זה תוצג בעיה עסקית של חישוב יחס המרה, כולל נתונים לדוגמה; בחלקו השני של המאמר (מוצג כמאמר נפרד), נדון ב-3 שיטות לפתרון הבעיה באמצעות שאילתות SQL.
אז ללא שהות נוספת, נשים את עצמנו בכיסא מדען הנתונים של חברת אינטרנט מסוימת, המציעה מוצר תוכנה במסגרת מנוי חודשי. לטובת תהליך המכירה, קיימת תקופת התנסות של שבועיים בחינם, ולאחר מכן נדרש לבחור במסלול החודשי המבוקש.
המשימה שלנו היא לחשב יחס המרה (Conversion Rate) של המשתמשים אשר הצטרפו למנוי החודשי לאחר תקופת ההתנסות.
בנוסף, נרצה לבחון כמה מהמשתמשים שהצטרפו להתנסות – אכן התנסו במוצר (ביקרו באתר המוצר לפחות פעם אחת במהלך תקופת ההתנסות).
במילים אחרות: המשימה היא למלא את הטבלה הבאה בנתוני משתמשים (נתונים לדוגמה):
|
השתמשו במוצר / שילמו |
לא הצטרפו בתשלום | הצטרפו בתשלום | סה"כ |
יחס המרה לתשלום |
|
לא השתמשו במוצר |
39 |
1 |
40 |
3% |
|
השתמשו במוצר |
49 |
11 |
60 |
18% |
|
סה"כ |
88 |
12 |
100 |
12% |
|
יחס המרה לשימוש במוצר |
60% |
בדוגמה האמורה, מתוך 100 משתמשים שנרשמו, 60 השתמשו בפועל במוצר.
מתוך ה-60 הללו, 11 הצטרפו בתשלום, קרי יחס המרה של 18%.
גם מתוך מי שכלל לא התנסה במוצר, היה לקוח אחד שהחליט להצטרף בתשלום (פחות סביר – אך עדיין אפשרי), ולכן יחס המרה בקבוצה זו הוא נמוך ועומד על 3%.
הנתונים אינם מובהקים סטטיסטית, אך עדיין ממחישים מגמה הגיונית מבחינה עסקית.
נניח שלרשותנו נתונים השמורים במספר טבלאות:
- טבלת נתוני משתמש (Users):
- Username – שם המשתמש (PK)
- Email – כתובת דואר אלקטרוני.
- Join_date – תאריך הרישום של המשתמש.
- טבלת מנויים/ לקוחות (Customers):
- Subscription_id – קוד המנוי (PK, למשתמש ייתכן רק מנוי אחד ברגע נתון).
- Username – שם המשתמש (FK).
- Plan_id – קוד תכנית המנוי של המשתמש (קוד 0 הוא תקופת ההתנסות ללא תשלום; 1-3 – תכניות בתשלום).
- subscription_start – מועד תחילת המנוי.
- Valid_until – מועד הסיום/תוקף של המנוי.
- טבלת נתוני ביקור/ שימוש בכלי (Sessions):
- Session_id – מזהה ייחודי של הביקור (PK).
- Username – שם המשתמש (FK).
- Session_start – מועד תחילת הביקור.
- Session_duration – משך הביקור.
בקוד (SQL Server) מופיעים נתוני משתמשים לדוגמה, אשר בהם נעשה שימוש לטובת המחשת שיטות השליפה.
לטובת מילוי הטבלה, נדרש לחשב מתוך כל המשתמשים בטבלת המשתמשים, לאילו משתמשים היו ביקורים במהלך תקופת ההתנסות, ומי מופיע גם בטבלת המנויים לאחר תקופת ההתנסות.
חדי העין שבינינו ודאי ישאלו את עצמם מדוע נדרשת טבלת המשתמשים לצורך המשימה הזו. ואכן, טבלת המשתמשים אינה נדרשת, שכן המשתמשים שנרשמו ונכנסו לתקופת ההתנסות יופיעו כבר בטבלת המנויים עם מנוי מסוג '0'. במציאות, ייתכנו מצבים של רישום שלא הסתיים (לדוגמה: נשלח למשתמש שנרשם מייל אישור – ושם נפסק התהליך), ולכן לא הופעל מנוי '0' עבור משתמשים מסוימים, אך לטובת הדוגמה שלנו נתעלם ממקרים כאלה.
אז עד כאן הצגת הבעיה.
בחלקו השני של המאמר (מוצג כמאמר נפרד) נדון בשיטות אפשריות לפתרון הבעיה.
בינתיים, אתם מוזמנים להוריד את הקודים של הנתונים, ולכתוב בעצמכם שאילתה המחשבת יחס המרה עבורם, אותה תוכלו לבדוק מול הפתרונות בחלקו השני של המאמר.
לתשומת לבכם: הנתונים בקוד שונים מאשר הדוגמה בטבלה, וכוללים מספר מקרים מעניינים שדורשים התייחסות.